Trie树敏感词检测及优化
1 摘要
业务涵盖C端用户提交文本输入功能,需要进行内容审查控制。商品评论等互动即时需要,要对文本进行敏感词检测及模糊处理, 并风险提示。实现基础敏感词检测,采用Trie树组织字典,针对业务场景进行组织多词典及歧义处理,达到更准确识别效果
2 方案设计
基于 Trie 树的词检查, 改造开源分词方案 analyze-ik, 实现敏感词检测。 模块功能需求: 1- 检测并去除评论中的敏感词汇 2- 词典包括基础初始配置,热加载 3-词典租户隔离
1.2 核心功能
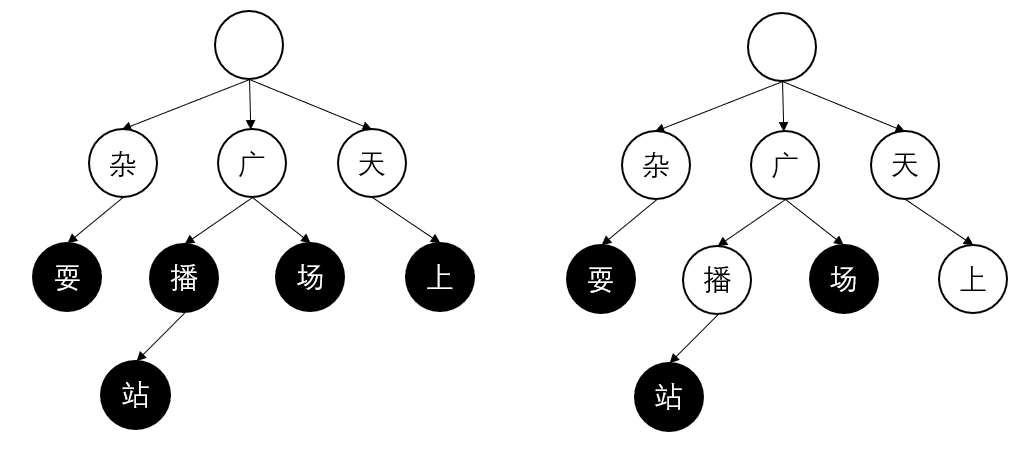
Trie (也称为基数树或前缀树)是基于树的数据结构,通常节点存储的是字符串。它和 HashMap 类似存儲的是关联数组结构,但它的每个节点存的是部分的字符串数据。HashMap 仅支持完 全匹配的查找,Trie更支持前缀匹配 (不然怎么叫前缀树)。例如在文本"场上有杂耍", 在哈希表中只能精准匹配"广场上有杂耍"这一句,字典树的搜索在搜到"广场","杂耍"更细 的词。 Trie 树构建, 它的实现是多叉树,每个节点是具体的字符及它的状态。如果构建"广场","广播",广播站","杂耍", 实际上的词典, 根节点为空, "广场" 在树中占两个节点, 黑色节点标识 这个词的结束。"广播"和"广场"有共同的节点"广,"广播"和"广播站"有共同的两个节点"广“和"播”。由于中文字数较多, 词普遍在四字内,则 可以认为树的宽度要远大于高度。
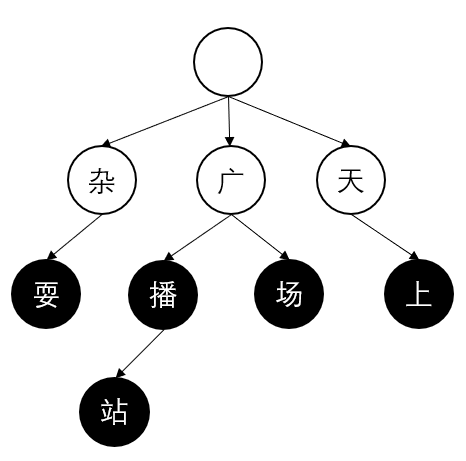
实现中 childrenArray/childrenMap存储下级节点, 当下级节点 小于一定值时使用数组, 超过才使用 map, 以达到节省内存空间目的,nodeState为节点状态标志, 是否是词的最后一个字符,nodeChar是字符本身

Trie树的建构是为了更高效的查找,前缀的数据结构下,符合DFA(确定性有限自动机)模型,下图是对应词库的状态转移图,图中同Trie树相似,每个节点表示一种状态,双线的状态是Final态,表示结束可以匹配输出一个关键词,有向的边表示事件,对应的是某个字符。
比如我们输入一个“广播”字符串,那从A开始,第一个字输入是“广”,则顺利到X,第二字是“播”,则到E,输出“广播”,没有后续输入了,便到此为止。同样一个匹配不到的例子,输入“天天早起”,同样从A开始,“天”转移到U, 下一个“天”没有匹配的事件,那么这次就找不到匹配的词了,“天天早起”就没有匹配的输出。
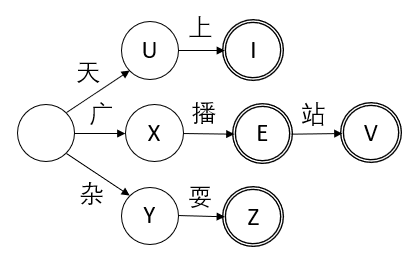
那么问题来了,“天天广播“有没有输出呢,按照之前的前缀匹配规则自然是没有的,但我们需要把“广播”这个词识别出来,所以此处不能是前缀匹配,也不是精准匹配,“天”虽然失败了,“广”字也要成功,那么就要从“广”字重新去匹配,这样就要每次逐字从头匹配或者回溯,去匹配失败点。这里采用类似广度遍历的方式,而非回溯,从原字符串逐字匹配字符,通过上下文进行传递,实现的穷举最大复杂度为O(n*m),但由于中文词普遍较短的特点,匹配串的m其实是个有限常值。
例子 “天天广播“ ,逐字演示它的匹配过程:
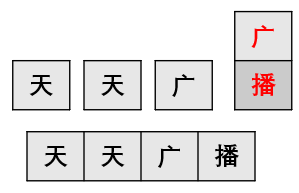
a.从字符串天(1)开始,匹配到A的“天”,将天(1)添加到上下文
b.读取第二个字天(2),上下文中U-天(1)没有下一个“天“的事件,不到下一轮。天(2) 匹配到A的“天”,将天(2)添加到上下文
c.读取第二个字广(3),上下文中U-天(2)没有下一个“天”的事件,不到下一轮。广(3) 匹配到A的“广”,将X-广(3)添加到上下文
d.读取第四个字播(4),上下文中X-广(3)有下一个“播”的事件,将E-广(3)播(4)添加到上下文。E-广(3)播(4)到达词尾,输出关键词“广播”到结果
e.到达字符串结尾,输出结果
1.2歧义优化
“下雨天留客天留我不留”,这是一句广为人知的典故,说是雨天客人求宿,主人留语送客,客巧解为“下雨天,留客天,留我不?留!”,而主意为“下雨,天留客,天留我不留。”汉语复杂,巧思断句,同时也为正确理解句子增加了难度。比如“你是刹笔“的”刹笔“在是典型的骂人词汇,但在“前车急刹笔者撞车了”,句中这两个字显然不是。
这里就需要区分常规词汇和敏感词汇,用多组Trie树对字符串进行多次标记,优先加载敏感词汇

这样通过多次标记定位语句中的敏感词汇,但问题也来了,刚说在“前车/急刹/笔者/撞车/了”这句话中,显然“刹笔“不是一个符合断句逻辑的词汇,这里就要通过歧义裁决处理”急刹笔者”这段冲突
方案A是 急刹/笔者
方案B是 刹笔
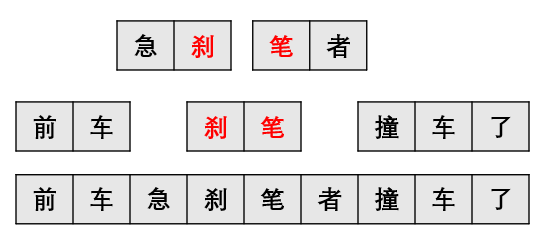
裁决逻辑的优先级:有效文本长度>词元个数>路径跨度>切分终点位置>敏感词占比>词长平均值>词元位置
方案A 有效文本长是4;方案B 有效文本长是2。
所以此处采用A切分方案,即 “前车/急刹/笔者/撞车/了”,不包含敏感词
1.3字典管理
1.3.1 字典热加载
敏感词库自定义添加同Trie树构建不再赘述。从树中删除某个词比如在树中热删除广播和天上,只需要把末字节点置为非末尾。后续词典跟随服务的重启等进行释放。
1.3.2 多租户内存优化
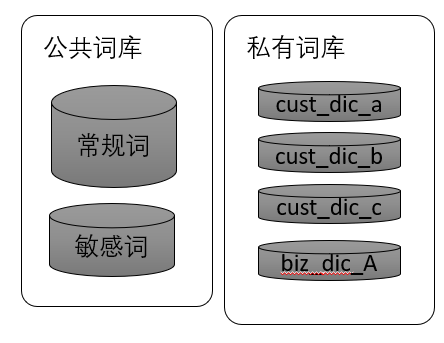
云服务模块需要针对不同租户定义不同的敏感词,常规词字典租户共库,行业分类词典及敏感词字典采用懒初始化。在多租户服务中,大量的前缀树会占用大量内存,使用租户id进行服务实例请求路由及词典池来节约实例内存。
3.性能测试
测试使用30M字共400K条新闻及评论语料作为检测文本,测试不同敏感词数下性能。可见在基于Trie树查找在词汇量上升情况下性能没有明显波动,符合预期,使用正则匹配时间线性增长。在总体正则耗时均高于Trie树查找。在内存使用上Trie树高于正则编译后对象大小
| Regex | Trie | |||
|---|---|---|---|---|
| dic_size | cost | mem | cost | mem |
| 100 | 16.2s | 11kb | 4.2s | 25kb |
| 1k | 154.5s | 69kb | 4.6s | 163kb |
| 10k | 1522.4s | 710kb | 5.4s | 882kb |